

1.准备的三台虚拟机
| IP | 规格 | 操作系统 | 主机名 |
|---|---|---|---|
| 192.168.188.128 | 4c4g | openEuler-24.03 | master |
| 192.168.188.129 | 4c4g | openEuler-24.03 | node1 |
| 192.168.188.130 | 4c4g | openEuler-24.03 | node2 |
2.安装前置准备工作
2.1 Kubernetes 使用主机名来区分集群内的节点,所以每台主机的 hostname 不可重名。修改 /etc/hostname 这个文件来重命名 hostname:
master节点命名为master,worker节点命名为node1,node2
hostnamectl set-hostname master
hostnamectl set-hostname node1
hostnamectl set-hostname node22.2 将 SELinux 设置为 permissive 模式(相当于将其禁用)
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config2.3 关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service2.4 关闭swap(避免内存交换至磁盘导致性能下降)
sudo swapoff -a
sudo sed -ri '/\sswap\s/s/^#?/#/' /etc/fstab2.5 配置主机名解析
cat >>/etc/hosts<< EOF
192.168.188.128 master
192.168.188.129 node1
192.168.188.130 node2
EOF2.6 开启转发 IPv4 并让 iptables 看到桥接流量
创建名为/etc/modules-load.d/k8s.conf 的文件,并且将 overlay和br_netfilter写入。这两个模块 overlay 和 br_netfilter 是 containerd 运行所需的内核模块。
(overlay模块:overlay模块是用于支持Overlay网络文件系统的模块。Overlay文件系统是一种在现有文件系统的顶部创建叠加层的方法,以实现联合挂载(Union Mount)。它允许将多个文件系统合并为一个单一的逻辑文件系统,具有层次结构和优先级。这样可以方便地将多个文件系统中的文件或目录合并在一起,而不需要实际复制或移动文件。
br_netfilter模块:br_netfilter模块是用于支持Linux桥接网络的模块,并提供了与防火墙(netfilter)子系统的集成。桥接网络是一种将不同的网络接口连接在一起以实现局域网通信的方法,它可以通过Linux内核的桥接功能来实现。br_netfilter模块与netfilter集成,可用于在Linux桥接设备上执行网络过滤和NAT(网络地址转换)操作。)
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
# 设置所需的 sysctl 参数,参数在重新启动后保持不变
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# 应用 sysctl 参数而不重新启动
sudo sysctl --system
# 运行以下命令确认模块是否正常被加载
lsmod | grep br_netfilter
lsmod | grep overlay
# 通过运行以下指令确认 net.bridge.bridge-nf-call-iptables、net.bridge.bridge-nf-call-ip6tables 和 net.ipv4.ip_forward 系统变量在你的 sysctl 配置中被设置为 1:
sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forward
若是出现net.ipv4.ip_forward=0则执行以下行:
sudo vim /etc/sysctl.conf
#添加或修改net.ipv4.ip_forward=1
#:wq保存文件,应用更改
sudo sysctl -p3.安装containerd
wget down.avi.gs/https://github.com/containerd/containerd/releases/download/v1.7.20/containerd-1.7.20-linux-amd64.tar.gz
#解压安装包
tar Czxvf /usr/local/ containerd-1.7.20-linux-amd64.tar.gz
#生成默认配置文件
mkdir -p /etc/containerd
containerd config default > /etc/containerd/config.toml
#使用systemd托管containerd
wget -O /usr/lib/systemd/system/containerd.service down.avi.gs/https://raw.githubusercontent.com/containerd/containerd/main/containerd.service
systemctl daemon-reload
systemctl enable --now containerd若是以上方式不行,可直接粘贴如下内容:
cat<<EOF|tee /etc/systemd/system/containerd.service
[Unit]
Description=containerd container runtime
Documentation=https://containerd.io
After=network.target local-fs.target
[Service]
ExecStartPre=-/sbin/modprobe overlay
ExecStart=/usr/local/bin/containerd
Type=notify
Delegate=yes
KillMode=process
Restart=always
RestartSec=5
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNPROC=infinity
LimitCORE=infinity
LimitNOFILE=1048576
# Comment TasksMax if your systemd version does not supports it.
# Only systemd 226 and above support this version.
TasksMax=infinity
OOMScoreAdjust=-999
[Install]
WantedBy=multi-user.target
EOF加载文件并启动
systemctl daemon-reload
systemctl enable --now containerd这里有两个重要的参数:
Delegate: 这个选项允许 containerd 以及运行时自己管理自己创建容器的 cgroups。如果不设置这个选项,systemd 就会将进程移到自己的 cgroups 中,从而导致 containerd 无法正确获取容器的资源使用情况。
KillMode: 这个选项用来处理 containerd 进程被杀死的方式。默认情况下,systemd 会在进程的 cgroup 中查找并杀死 containerd 的所有子进程。KillMode 字段可以设置的值如下。
control-group(默认值):当前控制组里面的所有子进程,都会被杀掉
process:只杀主进程
mixed:主进程将收到 SIGTERM 信号,子进程收到 SIGKILL 信号
none:没有进程会被杀掉,只是执行服务的 stop 命令
修改默认配置文件
# 开启运行时使用systemd的cgroup
sed -i '/SystemdCgroup/s/false/true/' /etc/containerd/config.toml
#重启containerd
systemctl restart containerd4.安装runc
用于根据OCI规范生成和运行容器的CLI工具
wget down.avi.gs/https://github.com/opencontainers/runc/releases/download/v1.1.13/runc.amd64
install -m 755 runc.amd64 /usr/local/sbin/runc5.安装CNI plugins
CNI(container network interface)是容器网络接口,它是一种标准设计和库,为了让用户在容器创建或者销毁时都能够更容易的配置容器网络。这一步主要是为contained nerdctl的客户端工具所安装的依赖 .
客户端工具有两种,分别是crictl和nerdctl, 推荐使用nerdctl,使用效果与docker命令的语法一致
wget down.avi.gs/https://github.com/containernetworking/plugins/releases/download/v1.5.1/cni-plugins-linux-amd64-v1.5.1.tgz
mkdir -p /opt/cni/bin
tar Cxzvf /opt/cni/bin cni-plugins-linux-amd64-v1.5.1.tgz
ll /opt/cni/bin/5.1 安装nerdctl
wget down.avi.gs/https://github.com/containerd/nerdctl/releases/download/v1.7.6/nerdctl-1.7.6-linux-amd64.tar.gz
tar xf nerdctl-1.7.6-linux-amd64.tar.gz
cp nerdctl /usr/local/bin/6.安装 kubeadm、kubelet 和 kubectl
你需要在每台机器上安装以下的软件包:
kubeadm:用来初始化集群的指令。
kubelet:在集群中的每个节点上用来启动 Pod 和容器等。
kubectl:用来与集群通信的命令行工具。
以下是1.29版本的仓库,如果要更换版本只需更新v版本号即可
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.29/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.29/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
EOF
yum clean all && yum makecache# 指定版本
yum install -y kubelet-1.29.4 kubeadm-1.29.4 kubectl-1.29.4 --disableexcludes=kubernetes
# 不指定版本
yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
systemctl enable --now kubelet6.1 配置ctictl
cat <<EOF|tee /etc/crictl.yaml
runtime-endpoint: unix:///run/containerd/containerd.sock
EOF7.初始化集群(7.6以前操作均为master节点操作)
7.1 将初始化配置写入yaml文件
kubeadm config print init-defaults > kubeadm-config.yaml7.2 修改初始化默认配置文件
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.188.128 # master的地址
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: master # master节点名称
taints: # 设置污点,不让pod运行在控制面
- effect: PreferNoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers # 设置国内镜像地址,加速镜像拉取
kind: ClusterConfiguration
kubernetesVersion: 1.29.7 # k8s安装的版本,记住要和你上面下载的版本号一致
networking:
podSubnet: 10.244.0.0/16 # 设置pod的网络地址,flannel默认是这个地址
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
scheduler: {}
---
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
cgroupDriver: systemd
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
containerRuntimeEndpoint: ""
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageMaximumGCAge: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
logging:
flushFrequency: 0
options:
json:
infoBufferSize: "0"
verbosity: 0
memorySwap: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
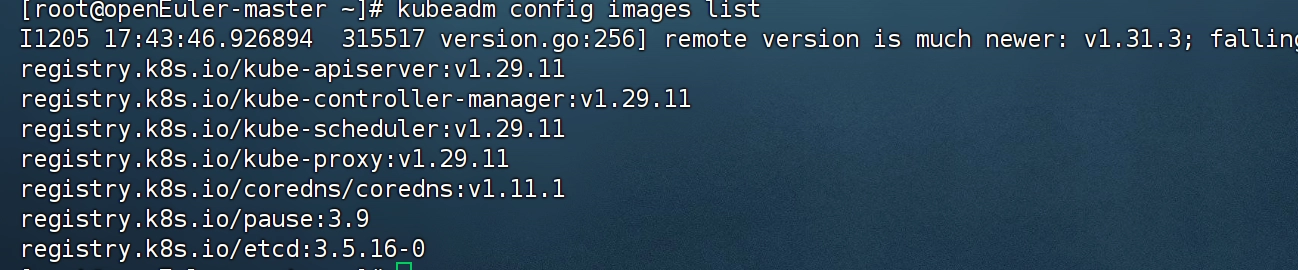
7.3 查看下载的镜像
kubeadm config images list --config kubeadm-config.yaml7.4 提前拉取镜像
kubeadm config images pull --config kubeadm-config.yaml7.5 初始化集群
kubeadm init --config kubeadm-config.yaml若初始化有问题可参考7.5.1的方案解决
7.5.1 解决方案
# 重定向一个标签 ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/pause:3.9 registry.k8s.io/pause:3.8 # 重新初始化 kubeadm init --config kubeadm-config.yaml --ignore-preflight-errors=all
其他节点也都执行以下操作
crictl pull registry.aliyuncs.com/google_containers/pause:3.9 && ctr -n k8s.io i tag registry.aliyuncs.com/google_containers/pause:3.9 registry.k8s.io/pause:3.87.6 配置kubectl访问集群
7.6.1 初始化成功后会出现以下信息:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.188.128:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:e855f5206b3cba86780d811b077b7674d8e2971eaedcc09bc1750e3d0ffaac80 7.6.2 根据提示配置信息:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
#在worker节点执行以下命令加入集群
kubeadm join 192.168.188.128:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:e855f5206b3cba86780d811b077b7674d8e2971eaedcc09bc1750e3d0ffaac80
#若忘记join信息,则可执行以下命令重新生成
kubeadm token create --print-join-command7.6.3 查看节点
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master noReady control-plane 54m v1.29.7
node1 noReady <none> 52m v1.29.7
node2 noReady <none> 52m v1.29.78.安装calico网络插件
Kubernetes 定义了 CNI 标准,有很多网络插件,这里选择最常用的 calico
# 直接下载到机器进行解压
wget -O calico.zip "https://bucket.aigan.cc/%E9%95%9C%E5%83%8F/calico.zip"
unzip calico.zip由于国内无法正常拉取docker镜像,因此需要手动导入
# 进入解压路径
cd calico
# 解压calico-images.tar.gz
tar -zxvf calico-images.tar.gz
# 使用ctr -n k8s.io images import导入
ctr -n k8s.io images import calico-images/calico-kube-controllers-v3.26.3.tar
ctr -n k8s.io images import calico-images/calico-cni-v3.26.3.tar
ctr -n k8s.io images import calico-images/calico-node-v3.26.3.tar
ctr -n k8s.io images import calico-images/calico-typha-v3.26.3.tar随后执行:kubectl apply -f calico-typha.yaml
9.新增master节点
如果是需要扩展master节点,需要执行以下步骤
# 新master节点
mkdir -p /etc/kubernetes/pki/etcd &&mkdir -p ~/.kube/
# 最开始的master节点上执行192.168.188.131为新的master节点
scp /etc/kubernetes/admin.conf root@192.168.188.131:/etc/kubernetes/
scp /etc/kubernetes/pki/ca.* root@192.168.188.131:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.* root@192.168.188.131:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.* root@192.168.188.131:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.* root@192.168.188.131:/etc/kubernetes/pki/etcd/
# 拿到上面kubeadm 生成的 join 命令在新的master上执行和工作节点的区别在于多了一个--control-plane 参数
kubeadm join 192.168.188.128:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:e855f5206b3cba86780d811b077b7674d8e2971eaedcc09bc1750e3d0ffaac80\
--control-plane




暂无评论内容